
python爬取bilibili视频
俺好久没用python的pip了, 今天pip3 install you-get的时候提示我要更新了。
You are using pip version 19.1.1, however version 20.0.2 is available. You should consider upgrading via the ‘python -m pip install –upgrade pip’ command. 然而直接打系统提示的那一行语句会报错更新不了,还是用清华源更香。
python -m pip install --upgrade pip -i https://pypi.tuna.tsinghua.edu.cn/simple/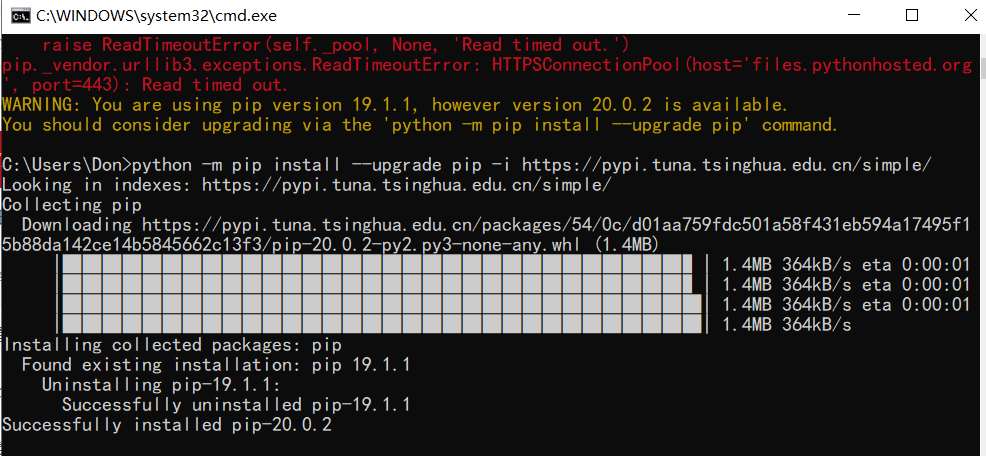
然后安装you-get(github上有31481个star⭐了 🐂🍺嗷)。
pip3 install you-getyou-get的使用非常简单,只要在终端输入形如”you-get URL(目标视频的url)”的命令就能够自动下载对应的视频。当然,you-get命令还有一些功能参数,我这里就不一一介绍了,大家可以去GitHub上查看官方demo,其中最为常用的有两个:
①–info/-i 这个参数的作用是解析出该地址下的视频信息,you-get命令仅会显示目标视频的基本信息,而不会开始下载视频。
②–output-dir/ -o可以设置路径,并使用–output-filename/ -O设置下载文件的名称。官网给出的示例如下:
you-get -o ~/Videos -O zoo.webm 'https://www.youtube.com/watch?v=jNQXAC9IVRw'当然还有一种方法就是cd进入目标文件夹下,再you-get下载,可以看到显示完目标视频的基本信息后会开始下载。

我不想用cmd了,我想用pyCharm,那么怎么在pyCharm里调用呢。我这里通过os调用的。
import os
os.system("you-get -o E://video/ https://www.bilibili.com/video/av79890922?spm_id_from=333.851.b_62696c695f7265706f72745f63696e657068696c65.9")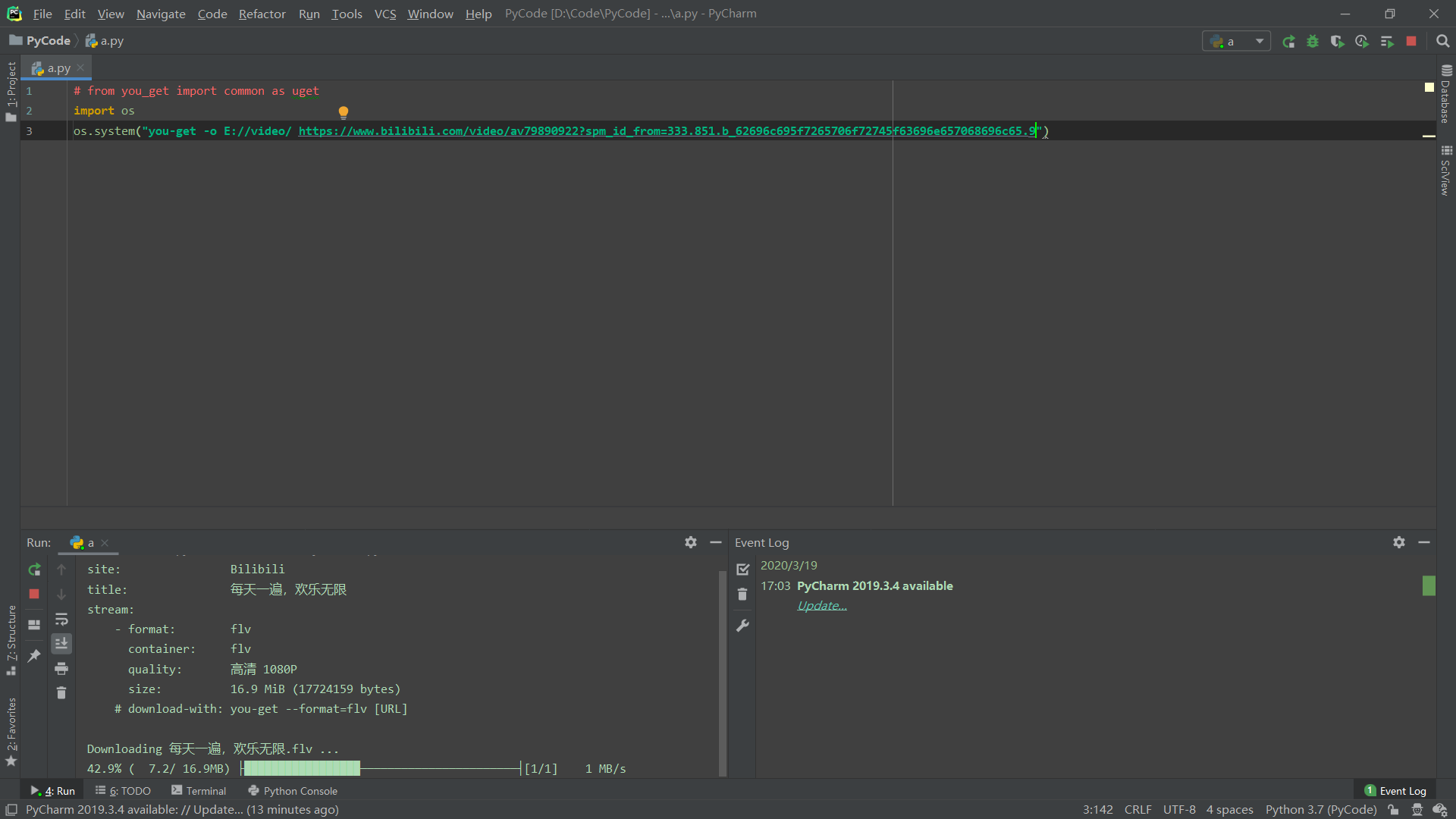
当然你也可以直接导入you_get库来进行爬取。
import sys
from you_get import common as you_get #导入you-get
directory = r'E:\video' #设置下载目录
url = 'https://www.bilibili.com/video/av55338853' #需要下载的视频链接
sys.argv = ['you-get','-o',directory,url] #sys传递参数执行下载,就像在命令行一样
you_get.main()至于怎么爬取一个系列的视频就自己写了,我这里就不举例啦。
2020.03.23更新!讲个笑话 哔哩哔哩为了保障稿件安全,把av号升级成了bv号 我的妈呀好慌呀
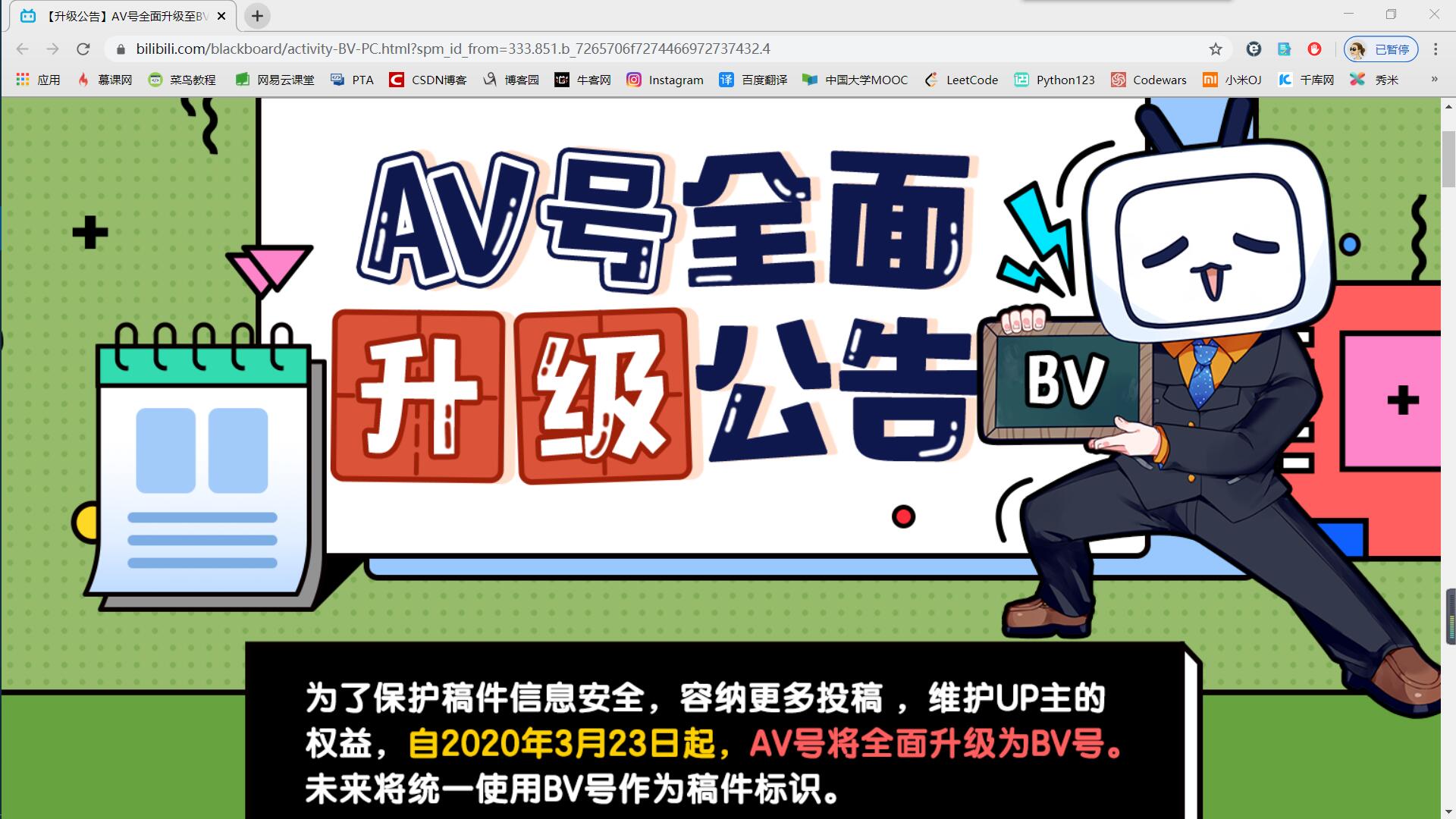
这种情况直接用you-get爬取会报错,不过不要慌 问题不大。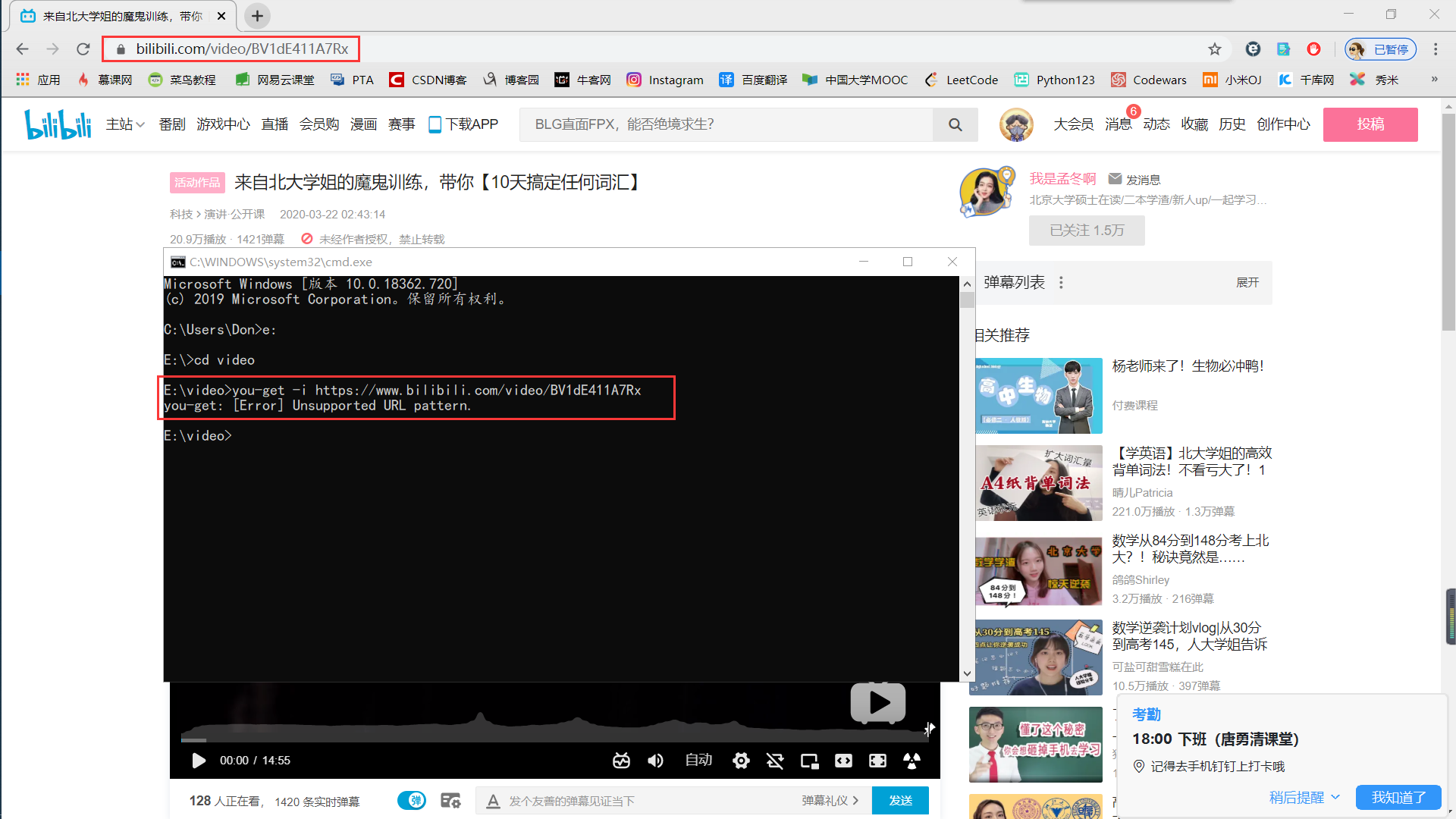
BV号可以理解为是加密后的AV号。我们只需要通过将BV号转换成AV号就可以重新you-get这个视频。
我用的浏览器是Google的Chorme,F12打开调试工具,点击console输入window.aid就可以知道AV号了。
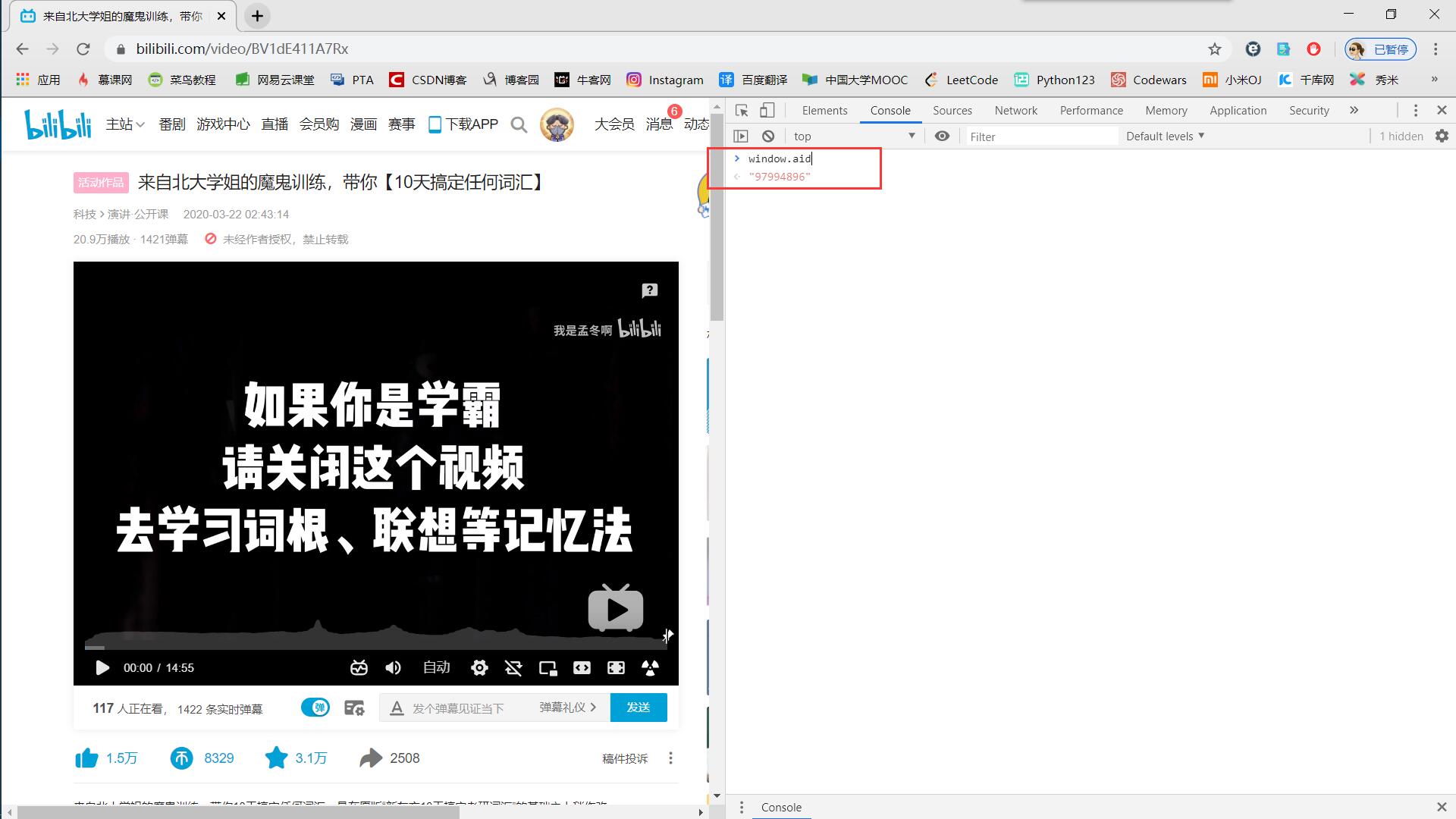
可以用这个av号试一下,看是不是同一个视频。
立即you-get -i URL 查看视频信息 我又好了,你呢?

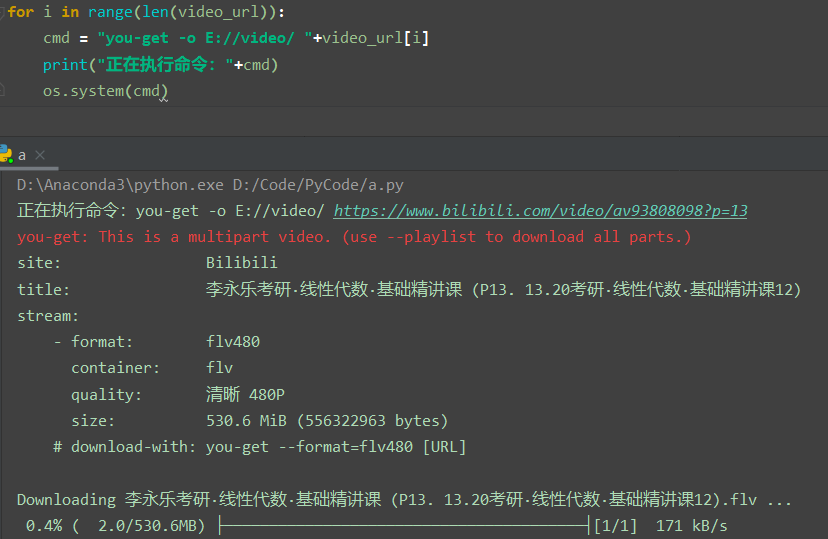
我这里用了一个线程优先级队列来实现多线程下载视频,真香。我用了6个Thread,在PyCharm显示的时候,可以看到最下面的那个进度条每2秒更新一次不同视频的下载进度条,不能同时更新下载进度条,这是因为直接用的you-get自带的进度条导致的。真的是多线程,用python自带的IDLE运行时可以看到会弹出6个cmd窗口同时下载。
import os
import sys
from you_get import common as you_get
import queue
import threading
import time
exitFlag = 0
class myThread(threading.Thread):
def __init__(self, threadID, name, q):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.q = q
def run(self):
print("开始线程:"+self.name)
downloading_video(self.name, self.q)
print("退出线程:" + self.name)
def downloading_video(threadName, q):
while not exitFlag:
queueLock.acquire()
if not workQueue.empty():
videoUrl = q.get()
queueLock.release()
# print("%s downloading %s" % (threadName, videoUrl))
#第一种方法用os调用you-get
cmd = "you-get -o E://video/ " + videoUrl
os.system(cmd)
#第二种方法用sys调用you-get ...我觉得没上面的方便
# path = 'E:\\video\' #设置下载目录
# sys.argv = ['you-get','-o',path,videoUrl] #sys传递参数执行下载
# you_get.main()
else:
queueLock.release()
time.sleep(2)
threadList = ["Thread-1", "Thread-2", "Thread-3", "Thread-4", "Thread-5", "Thread-6"] #线程个数
videoList = [
'https://www.bilibili.com/video/av97994896',
'https://www.bilibili.com/video/av98149221',
'https://www.bilibili.com/video/av啥啥啥',
'https://www.bilibili.com/video/av啥啥啥',
'https://www.bilibili.com/video/av啥啥啥',
'https://www.bilibili.com/video/av啥啥啥',
'https://www.bilibili.com/video/av啥啥啥',
'https://www.bilibili.com/video/av啥啥啥',
'https://www.bilibili.com/video/av啥啥啥'
] #待下载的视频列表
queueLock = threading.Lock()
workQueue = queue.Queue(30)
threads = []
threadID = 0
if __name__ == '__main__':
# 创建新线程
for tName in threadList:
thread = myThread(threadID, tName, workQueue)
thread.start()
threads.append(thread)
threadID += 1
# 填充队列
queueLock.acquire()
for word in videoList:
workQueue.put(word)
queueLock.release()
# 等待队列清空
while not workQueue.empty():
pass
# 通知线程是时候退出
exitFlag = 1
# 等待所有线程完成
for t in threads:
t.join()
print("退出主线程")

原文链接:python爬取bilibili视频
麦芽雪冷萃 版权所有,转载请注明出处。
























还没有任何评论,你来说两句吧!